Tutorial 3 — Circadian analysis
PlaceholderAuto-generated fromtutorial_notebook/3_Circadian_tutorial.ipynb. Executed against the seaborn canvas so every figure is inline as a static PNG. Plotly-only cells are kept for context and marked as placeholders —populatedfor the interactive version, run the source notebook.
Ethoscopy - Circadian tutorial
This tutorial assumes you have some basic knowledge of Ethoscopy, if you don't please head to the overview tutorial first.
This tutorial will walk through the array of circadian analysis methods ethoscopy contains, from actograms and anticipation scores, to periodograms. Whilst the tutorial will keep things basic there will be some assumed knowlege about circadian rythmn.
1. Load the dummy dataset
import ethoscopy as etho
# This tutorial required version 1.2.0 or greater
etho.__version__
'2.0.5'
One-time setup: fetch the tutorial datasets
The tutorial pickle files (~36 MB total, dominated by publish_tutorials.py…overview_data.pkl) are not bundled with the PyPI package, to keep pip install ethoscopy lean.
Run the cell below once per environment to download them into the installed package directory. Subsequent runs are idempotent (already-present files are skipped).
You can also fetch them manually from https://github.com/gilestrolab/ethoscopy/tree/main/src/ethoscopy/misc/tutorial_data.
# Idempotent: skips files that are already present.
import ethoscopy as etho
etho.download_tutorial_data()
[skip] overview_data.pkl (already present)
[skip] overview_meta.pkl (already present)
[skip] circadian_data.pkl (already present)
[skip] circadian_meta.pkl (already present)
[skip] 4_states_F_WT.pkl (already present)
[skip] 4_states_M_WT.pkl (already present)
Tutorial data ready in: /home/gg/.cache/ethoscopy/tutorial_data
PosixPath('/home/gg/.cache/ethoscopy/tutorial_data')
# import this function to get the tutorial dataset
from ethoscopy.misc.get_tutorials import get_tutorial
# We'll be using a circadian specific dataset this time that was generated previously, enter 'circadian' as the argument to grab it
# Load the data and metadata, and then intialise it into a behavpy object
data, metadata = get_tutorial('circadian')
df = etho.behavpy(data, metadata, palette = 'Set2', canvas = 'seaborn', check = True)
dfp = etho.behavpy(data, metadata, palette = 'Set2', canvas = 'plotly', check = True)
2. Looking at the data
# Lets have a look at what we're working with
df.summary()
behavpy table with:
individuals 32
metavariable 3
variables 2
measurements 415040
# In the meta we can see the specimens are split into different experimental groups, these are the groups we will want to look at
df.meta
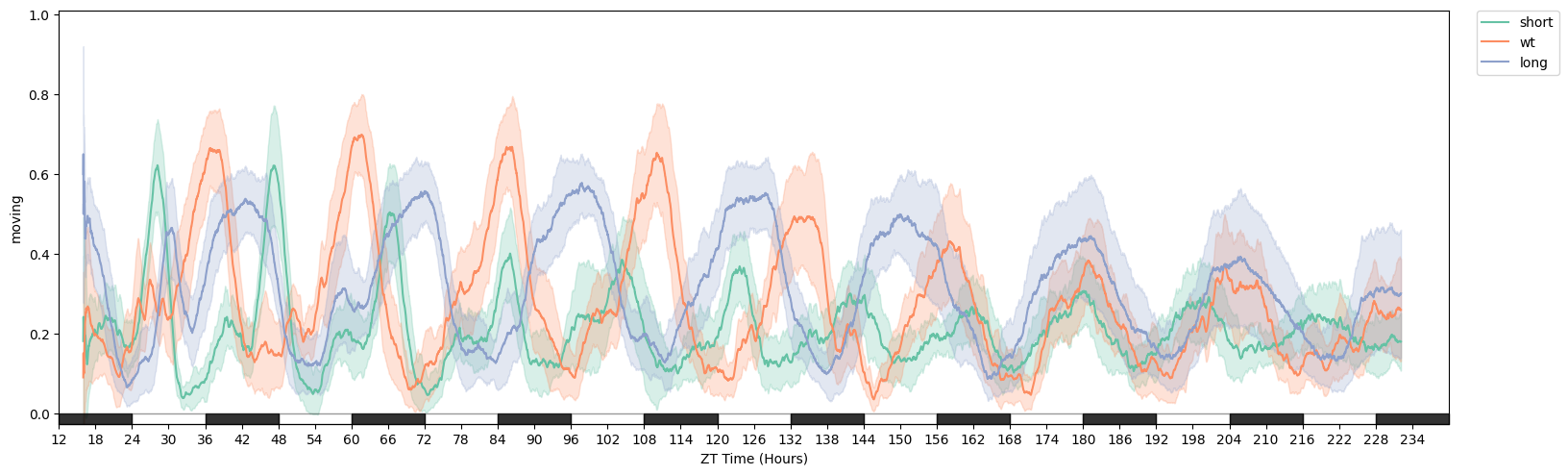
# We can see from plotting the movement data that they a different rythmn
fig = df.plot_overtime('moving', facet_col = 'period_group', avg_window=180)
3. Actograms
Actograms are a simple visual way to see changes in activity over multiple days. With ethoscopy you have two ways of viewing your actograms, you can create one for every specimen or you can average it over the whole dataframe / experimental group.
Due to the interactive nature of Plotly plot objects, they don't lend themselves well to actograms which are multiple bar plots. Due to this, no matter the selected canvas, the plot will be generated in Seaborn.
Grouped Actograms
# Lets create an averaged Actogram for each period group using the .plot_actogram() method
# Choose the column with the movement data, the averaging window you'd like to use, and then the column to facet by
fig = df.plot_actogram(
mov_variable = 'moving',
bin_window = 5, # the default is 5, but feel free to change it to smooth out the plot or vice versa
facet_col = 'period_group',
facet_arg = ['short', 'wt', 'long'],
title = 'Grouped Actogram')
# If you dont give an arugment to facet_col then a single actogram will be plotted that is an average of all your data
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1611: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(

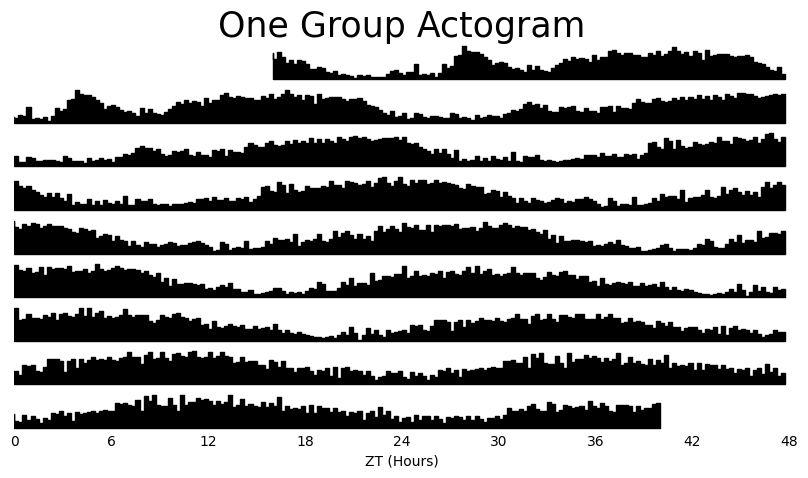
fig = df.xmv('period_group', 'long').plot_actogram(
mov_variable = 'moving',
bin_window = 15, # the default is 5, but feel free to change it to smooth out the plot or vice versa
title = 'One Group Actogram'
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1611: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
Tiled Actograms
# Although we can already see the differences between the groups, often when you don't already have a nicely curated dataset it's nice to see everything
# When plotting all specimens the default is to take the specimens IDs as each plots title. However, these names can be uniformative at first glance and we might want
# to replace them with more informative labels. Lets create some for this example
# Remember to access the metadata part of the dataframe just add .meta
# We can create a new column by combining two others. However, the regio_id is a integer and not a string, so we have to convert it first
df.meta['tile_labels'] = df.meta['period_group'] + '_' + df.meta['region_id'].apply(lambda l: str(l))
# plot_actogram_tile will plot every specimen in your behavpy dataframe
fig = df.plot_actogram_tile(
mov_variable = 'moving',
labels = 'tile_labels',
title = 'Tiled Actogram')
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1611: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(

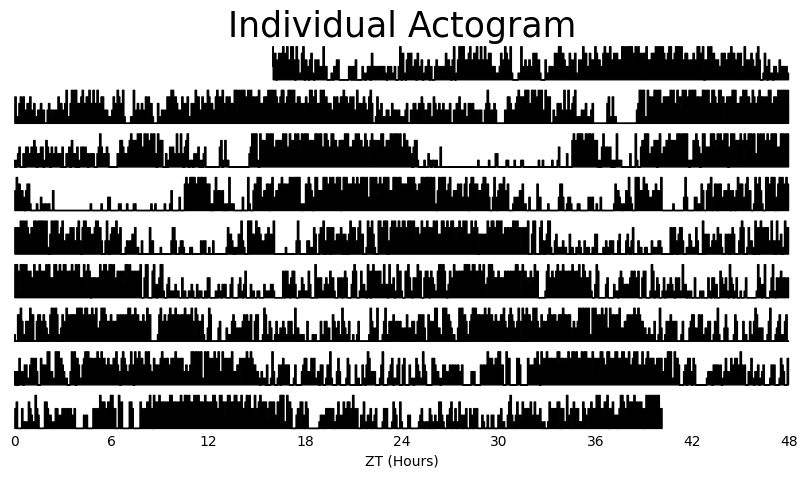
# If you just want to see produce a single actogram for one specimen then filter the dataframe before and then call .plot_actogram()
temp_df = df.xmv('id', '2017-01-16 08:00:00|circadian.txt|01')
fig = temp_df.plot_actogram(
mov_variable = 'moving',
title = 'Individual Actogram')
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1611: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
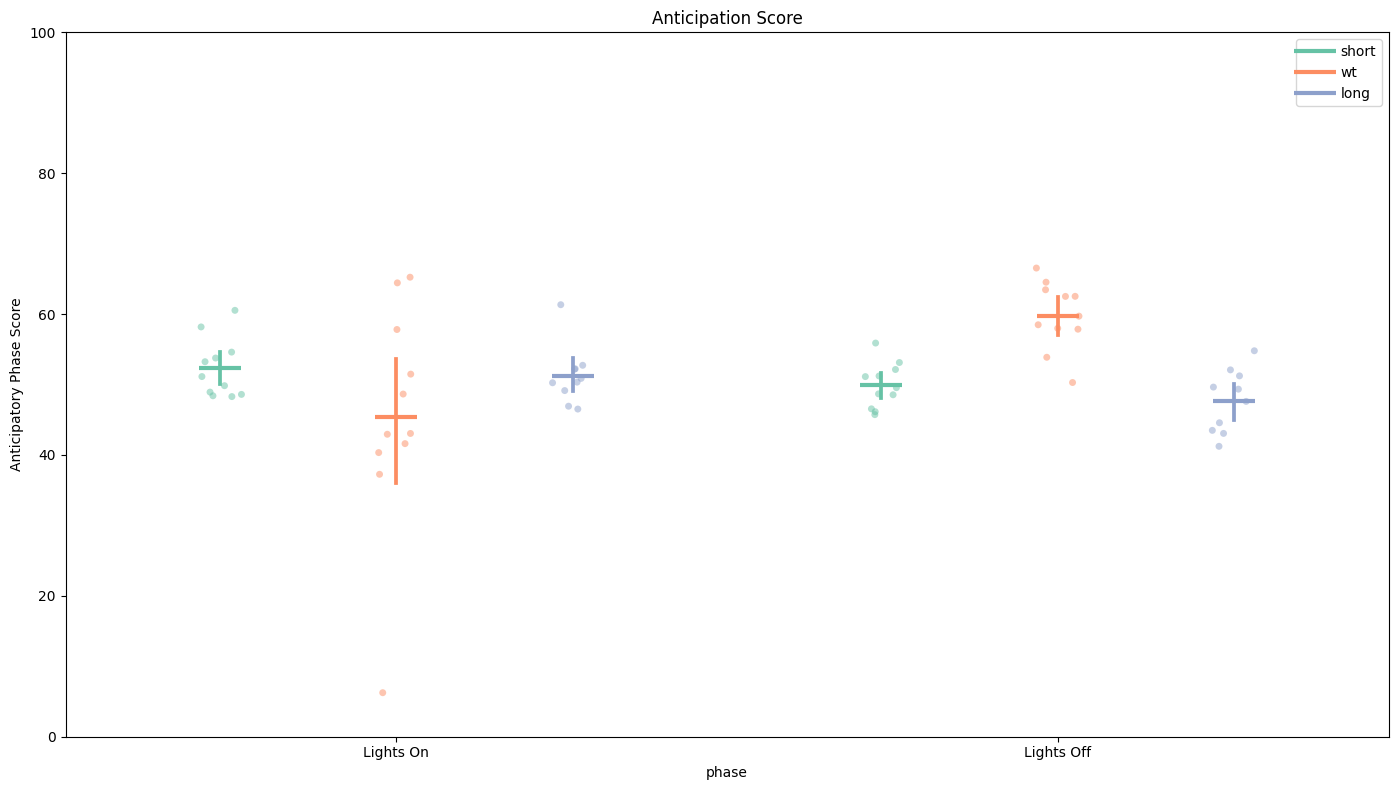
4. Anticipation Score
The anticipation score is the ratio of the final 3 hours of activity compared to the whole 6 hours of activity prior to lights on/off. This gives us a way of quantifying the morning and evening peaks of activity that are hallmarks of Drosophila circadian rythmn.
# Simply call the plot_anticipation_score() method to get a box plot of your results
# the day length and lights on/off time is 24 and 12 rarangeespectively, but these can be changed if you're augmenting the environment
fig, stats = df.plot_anticipation_score(
variable = 'moving',
facet_col = 'period_group',
facet_arg = ['short', 'wt', 'long'],
day_length = 24,
lights_off = 12,
title = 'Anticipation Score')
# Here we can see only the WT flies have over 50% of their activity in the final 3 hours before lights off. This shows that they are anticipating the evening feeding time correctly,
# whereas the others fail to do so. Lights On score is the same across the groups.
4. Periodograms
Periodograms are essential for definitely showing periodicity in a quantifiable way. Periodograms often make use of algorithms created from spectral analysis, to decompose a signal into its component waves of varying frequencies. This has been adopted to behavioural data, in that it can find a base rythmn over several days from what is usually unclean data.
Ethoscopy has 5 types of periodograms built into its behavpy_periodogram class, which are 'chi squared' (the most commonly used), 'lomb scargle', fourier, and 'welch' (all based of of the fast fourier transformation (FFT) algorithm) and 'wavelet' (using FFT but maintaining the time dimension).
Try them all out on your data and see which works best for you.
# Before we can access all the methods we first must compute our periodogram, so always call this method first
# For this example we'll compare the chi squared periodogram with lomb scargle
# the periodogram can only compute 4 types of periodograms currently, choose from this list ['chi_squared', 'lomb_scargle', 'fourier', 'welch']
per_chi = df.periodogram(
mov_variable = 'moving',
periodogram = 'chi_squared',
period_range = [10,32], # the range in time (hours) we think the circadian frequency lies, [10,32] is the default
sampling_rate = 15, # the time in minutes you wish to smooth the data to. This method will interpolate missing results
alpha = 0.01 # the cutoff value for significance, i.e. 1% confidence
)
per_lomb = df.periodogram(
mov_variable = 'moving',
periodogram = 'lomb_scargle',
period_range = [10,32],
sampling_rate = 15,
alpha = 0.01
)
# Hint! Sometimes increasing the sampling_rate can improve you're periodograms. On average we found 15 to work best with our data, but it can be different for everyone.
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1611: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1459: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
data.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1611: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1459: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
data.groupby("id", group_keys=False).apply(
# each periodogram should have atleast the columns period, power, and sig_threshold
per_chi
7072 rows × 4 columns
# We can see that lomb_scargle has more rows that chi_squared. This is because the loomb scargle returns a list of freqeuncies between our period range that it determines best represents the
# data given. However, chi squared will just the binned windows we give it from the sampling_rate
# Lomb scargle has been reported to be more accurate with chi squared sometimes giving false positives, see: https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1008567
# However sometimes it's the only one that works, so try all of them
per_lomb
9536 rows × 3 columns
Plotting the Periodograms
Tiled Plots
# To get a good understanding of each individual specimen you might want to plot the periodograms of each individual
# Like the actogram_tile method we can rely on the ids of each specimen or we can use the labels we created
fig = per_chi.plot_periodogram_tile(
labels = 'tile_labels',
find_peaks = True, # make find_peaks True to add a marker over significant peaks
title = 'Tiled Chi Squared Periodogram'
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:2948: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
data.groupby("id", group_keys=False).apply(
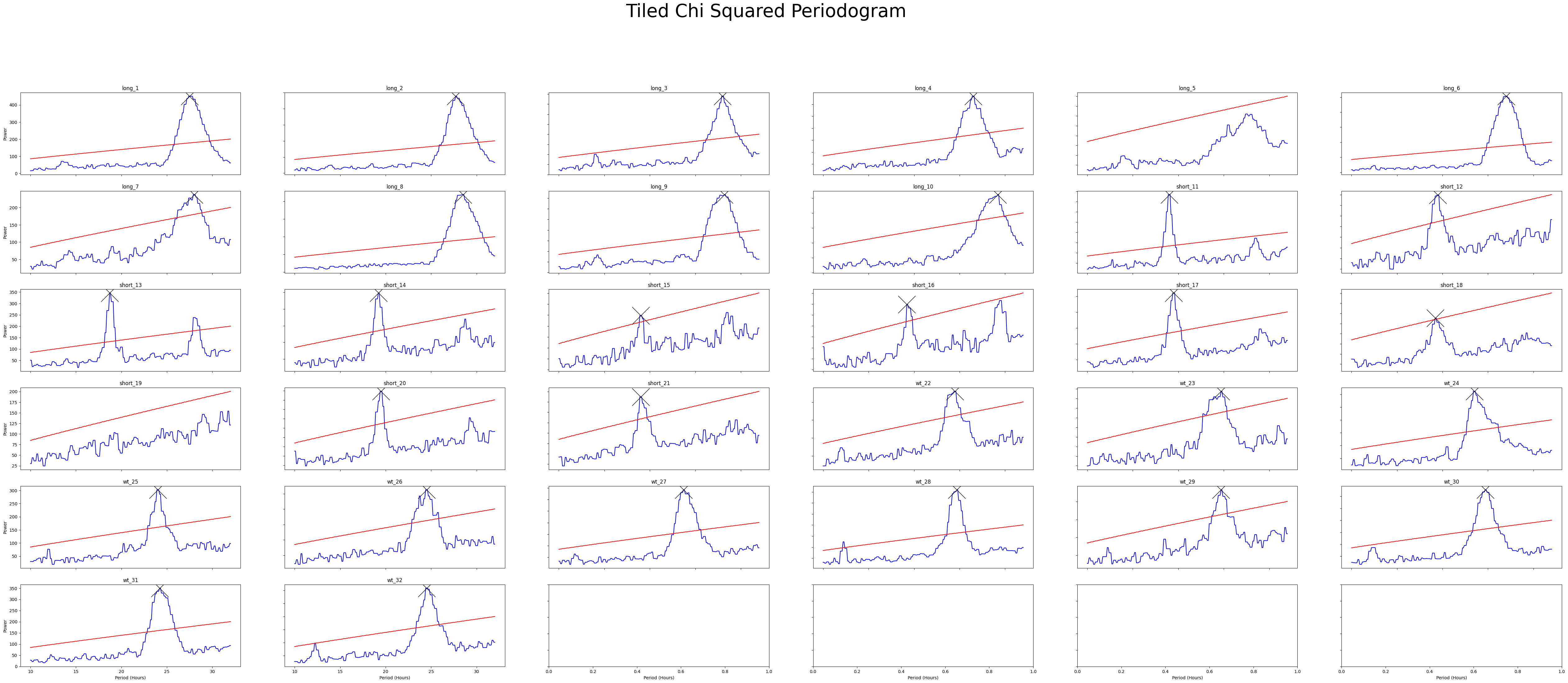
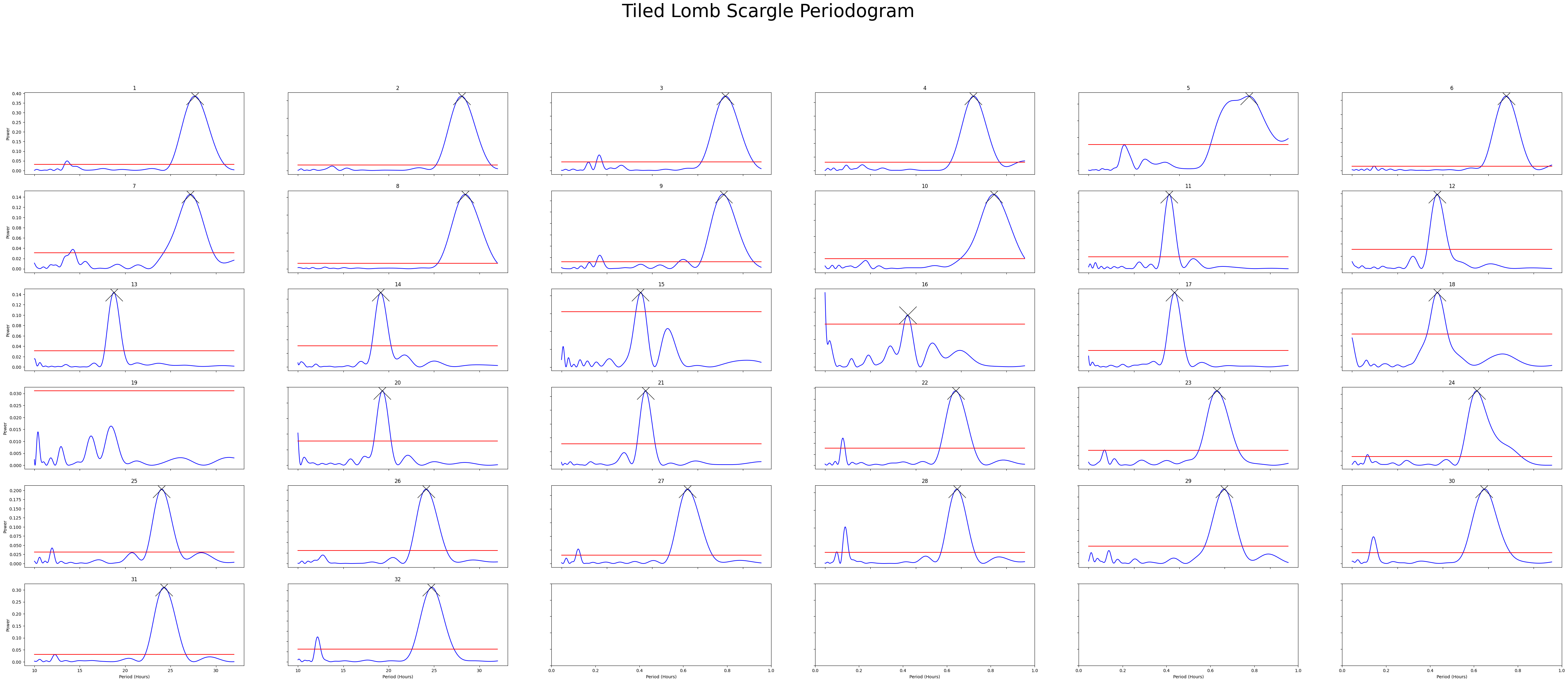
fig = per_lomb.plot_periodogram_tile(
labels = 'region_id',
find_peaks = True, # make find_peaks True to add a marker over significant peaks
title = 'Tiled Lomb Scargle Periodogram'
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:2948: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
data.groupby("id", group_keys=False).apply(
Grouped Plots
# Lets have a looked at them averaged across the groups
fig = per_chi.plot_periodogram(
facet_col = 'period_group',
facet_arg = ['short', 'wt', 'long'],
title = 'Grouped Chi Squared Periodogram'
)
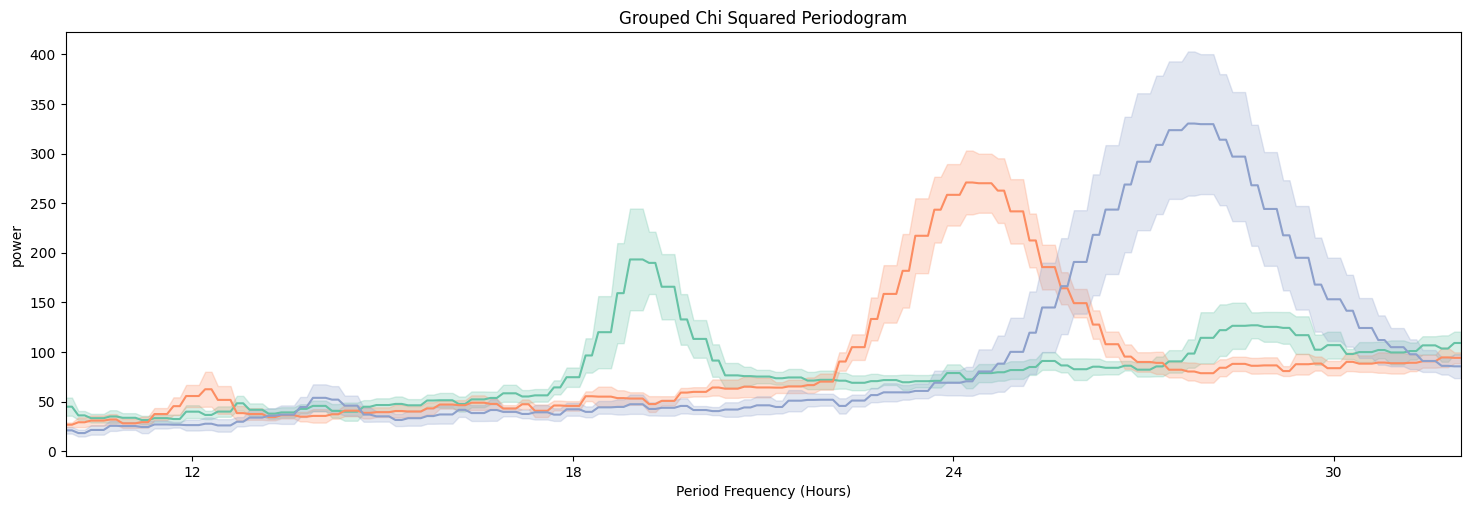
fig = per_lomb.plot_periodogram(
facet_col = 'period_group',
facet_arg = ['short', 'wt', 'long'],
title = 'Grouped Lomb Scargle Periodogram'
)
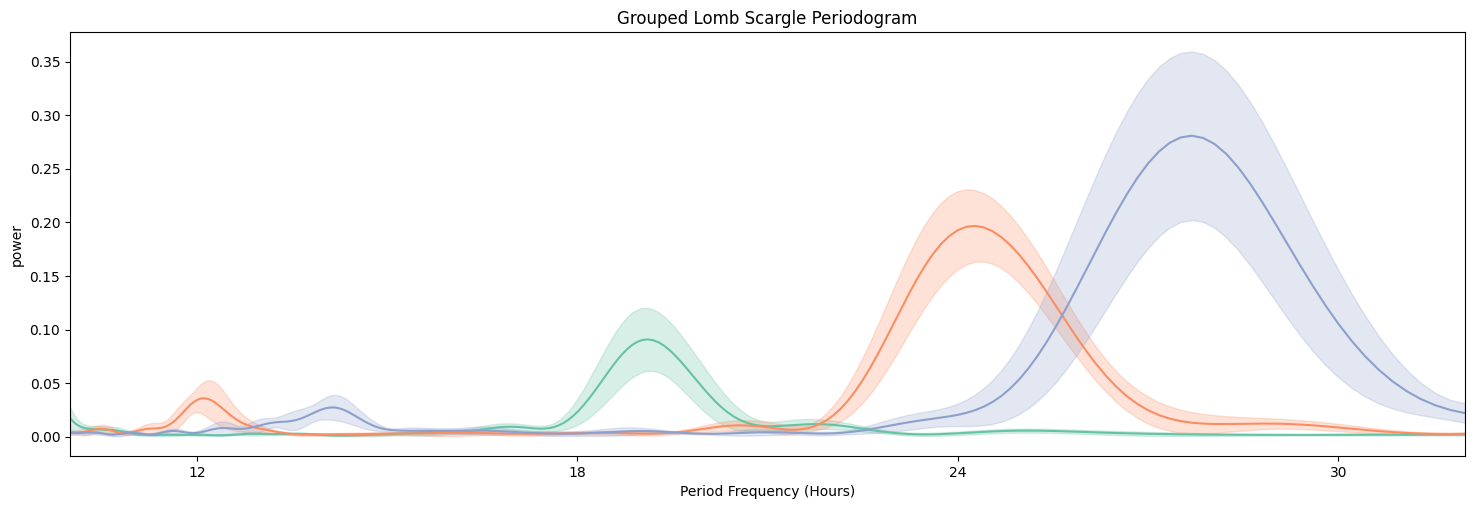
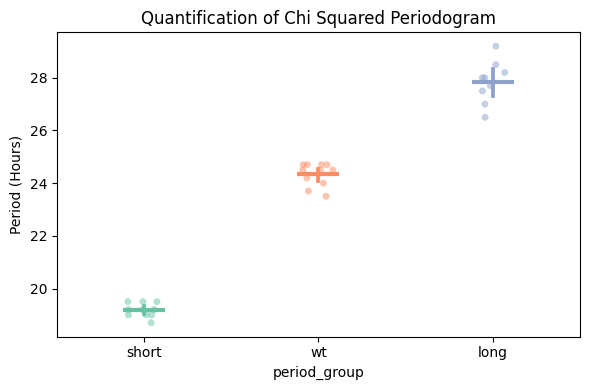
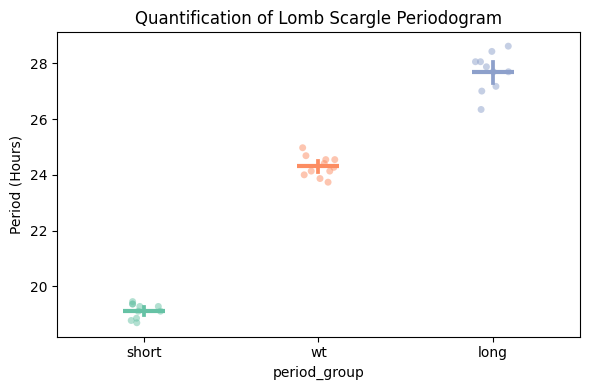
We can see from both Chi Squared and Lomb Scargle that the different groups have periodicities of about 19, 24, and 27 respectively. But now we want to quantify this.
Quantify Periodogram
# Quantify the periodograms by finding the highest power peak and comparing it across specimens in a group
# call .quantify_periodogram() to get the results
fig, stats = per_chi.plot_periodogram_quantify(
facet_col = 'period_group',
facet_arg = ['short', 'wt', 'long'],
title = 'Quantification of Chi Squared Periodogram'
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:2948: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
data.groupby("id", group_keys=False).apply(
fig, stats = per_lomb.plot_periodogram_quantify(
facet_col = 'period_group',
facet_arg = ['short', 'wt', 'long'],
title = 'Quantification of Lomb Scargle Periodogram'
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:2948: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
data.groupby("id", group_keys=False).apply(
# You can find the peaks in your periodograms without plotting, use .find_peaks()
# Find peaks adds a column to your periodogram dataframe with the rank of your peak. I.e. false = no peak, 2 = 2nd highest peak, 1 = highest peak
per_chi_peaks = per_chi.find_peaks(
num_peaks = 3 # maximum number of peaks you want returned, if there are less than your given number then only they will be returned
)
#Lets have a look at the peaks
per_chi_peaks[per_chi_peaks['peak'] != False]
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:2948: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
data.groupby("id", group_keys=False).apply(
Wavelets
The final periodogram is wavelets, which preserve the time dimension when finding the underlying frequencies. This means you can see how periodcity changes over the course of a long experiment
# Wavelet plots are intensive to plot usually due to the amount of points. Therefore the .wavelet function will compute and plot just one wavelet transformation, averaging all the data in your dataframe
# It's therefore recommended you filter prior to calling the function, either by groups or to individual specimens
# This method is powered bythe python package pywt, Head to https://pywavelets.readthedocs.io/en/latest/ for information about the pacakage and the other wavelet types
wt_df = df.xmv('period_group', 'wt')
fig = wt_df.plot_wavelet(
mov_variable = 'moving',
sampling_rate = 15, # increasing the sampling rate will increase the resolution of lower frequencues (16-30 hours), but lose resolution of higher frequencies (2-8 hours)
scale = 156, # the defualt is 156, increasing this number will increase the resolution of lower frequencies (and lower the high frequencies), but it will take longer to compute
wavelet_type = 'morl', # the default wavelet type and the most commonly used in circadian analysis. Head to the website above for the other wavelet types or call the method .wavelet_types() to see their names
title = 'Wavelet: WT'
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1611: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1459: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
data.groupby("id", group_keys=False).apply(
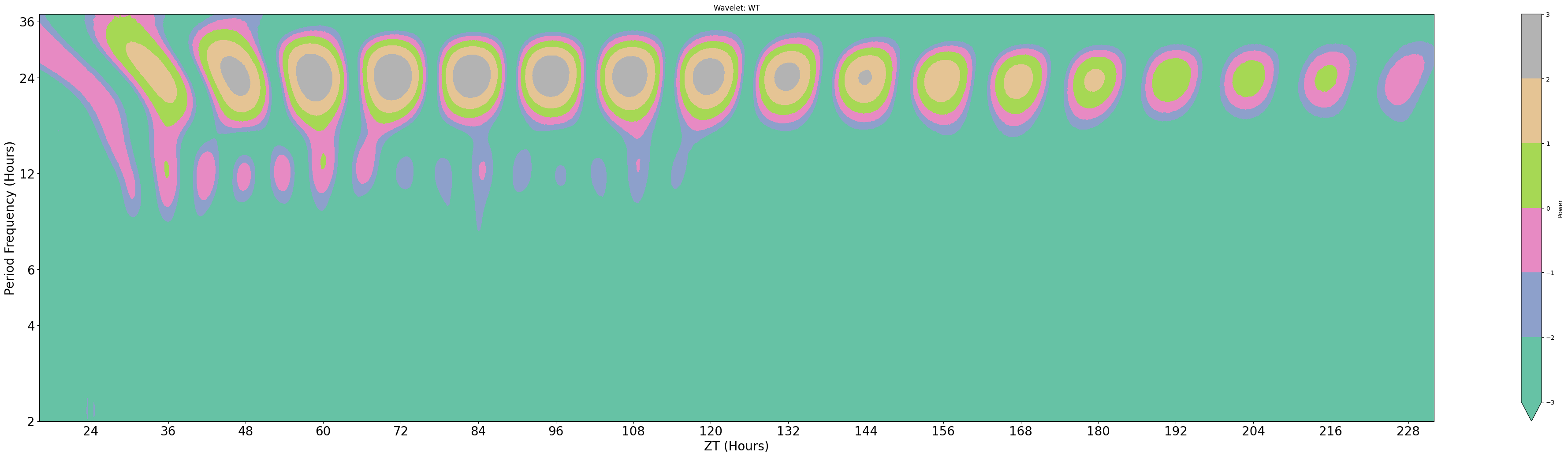
Areas of organge/red have high scores for the freqencies on the y-axis. Due to trying to fit all of the frequencies of the y-axis in the results are plotted on a natural log scale, this makes it hard to find accurate changes in periodicity. However we can see how it changes over time, which here seems to decrease slightly. (The edge cases of wavelets tend to have the lowest scores due to the effect of windowing, so the drop is not unexpected)
Here we've walked you through how to use behavpy to perform circadian analysis on your data, go forth and analyse