Tutorial 2 — HMM: hidden behavioural states
Auto-generated from
tutorial_notebook/2_HMM_tutorial.ipynb. Executed against the seaborn canvas so every figure is inline as a static PNG. Plotly-only cells are kept for context and marked as placeholders — for the interactive version, run the source notebook.
Ethoscopy - HMM tutorial
This tutorial assumes you have some basic knowledge of Ethoscopy, if you don't please head to the overview tutorial first.
For this tutorial we will be training a Hidden Markov Model (HMM) using an ethoscopy wrapper class for the python package Hmmlearn, see https://hmmlearn.readthedocs.io/en/latest/ for more details on what this excellent package can do. A good introduction to HMM's is available here: https://web.stanford.edu/~jurafsky/slp3/A.pdf
Ethoscopy adapts their Categorical HMM, as such the model can only be trained using discrete data represented as integers starting with 0 as the first. I.e. "Cat 1 = 0, Cat 2 = 1, ..."
At the Gilestro lab we train our model using movement data from the Ethoscope system, using tested parameter limits for velocity as movement we categorise movement as either True or False, or 1 or 0. During the setup we found data binned to 60 seconds (1 min) and then trained best recapitulated the sleep of CS drosophila.
1. Load the dummy dataset
import pickle
import ethoscopy as etho
import numpy as np
# This tutorial required version 1.1.8 or greater
etho.__version__
'2.0.5'
One-time setup: fetch the tutorial datasets
The tutorial pickle files (~36 MB total, dominated by overview_data.pkl) are not bundled with the PyPI package, to keep pip install ethoscopy lean.
Run the cell below once per environment to download them into the installed package directory. Subsequent runs are idempotent (already-present files are skipped).
You can also fetch them manually from https://github.com/gilestrolab/ethoscopy/tree/main/src/ethoscopy/misc/tutorial_data.
# Idempotent: skips files that are already present.
import ethoscopy as etho
etho.download_tutorial_data()
[skip] overview_data.pkl (already present)
[skip] overview_meta.pkl (already present)
[skip] circadian_data.pkl (already present)
[skip] circadian_meta.pkl (already present)
[skip] 4_states_F_WT.pkl (already present)
[skip] 4_states_M_WT.pkl (already present)
Tutorial data ready in: /home/gg/.cache/ethoscopy/tutorial_data
PosixPath('/home/gg/.cache/ethoscopy/tutorial_data')
# import this function to get the tutorial dataset
from ethoscopy.misc.get_tutorials import get_tutorial
# We'll be using the same dataset as in the overview tutorial, so use the same function below with the argument 'overview'
# Load the data and metadata, and then intialise it into a behavpy_HMM
data, metadata = get_tutorial('overview')
df = etho.behavpy(data, metadata, canvas = 'seaborn', check = True)
dfp = etho.behavpy(data, metadata, canvas = 'plotly', check = True)
2. Curate the Data
# First we'll call the method to remove dead specimens
# df = df.curate_dead_animals()
# We'll also remove the specimen we noticed in the overview tutorial that was missed by the above method
df = df.remove('id', '2016-04-04_17-39-05_009aee|02')
# As we saw in the overview tutorial the dataset has half the specimens sleep deprived later in the experiment
fig = df.heatmap(variable = 'asleep')
fig.show()
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/tmp/ipykernel_554230/4143008177.py:3: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
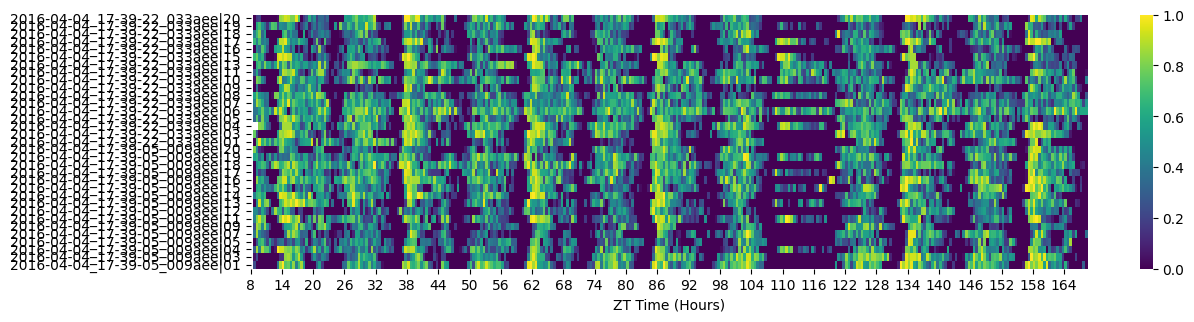
# When training a HMM you want a specimens basline data as normal conditions, so for this excerise we'll want to trim the dataset
# We can see from the heatmap that the sleep deprivation begins at 108 hours (ZT 12), we'll also trim the first day data as the specimens settle in
df = df.t_filter(start_time = 24, end_time = 108)
# It's also key to have as few missing values as possible when training the data, as the model assumes a consitent time gap between each point
# Our dataset now has 3.5 days with time bins of 60 seconds, so if a specimen was to have maximum data points for that time they would have
# (86400/60) * 3.5 rows of data. Lets not take any chances and only take specimens with that exact amount
df = df.curate(points = (86400/60) * 3.5)
# If any of the data passed to the model to be trained contains NaN values it will throw an error
# So lets check our data for NaN values
df['moving'][df['moving'].isnull()]
id
2016-04-04_17-39-22_033aee|01 NaN
Name: moving, dtype: object
# We have one NaN value, which is enough to crash the whole thing!
# Luckily pandas has built in methods to replace NaN values, use ffill() (from the row above) for forward fill NaNs or bffill() to back fill (from the row below).
# Lets to see if it worked
df['moving'][df['moving'].isnull()]
id
2016-04-04_17-39-22_033aee|01 NaN
Name: moving, dtype: object
3. Setup
# Now we're setup we can call the training method
# iterations is the number of times you want to iterate and train starting with new transiton and emission probabilities. It's recommended to have this higher than 3
# but for the tutorial we'll keep it low for the sake of time. More iterations mean you're more likely to find the best fitting model and
# hmm_iterations is the number of times the HMM will iterate with newer parameters before stopping
# tol is the the value for the difference in log liklihood after each iteration, once the value equals your input the model will stop updating the parameters
# After each time the transiton and emission probabilities are randomised and a model is produced, a score of logliklihood will be generated against 10% of the data,
# each new model will be scored against this and the best one will be returned at the end. Change the size of the test batch with test_size
# Save the best model to your local as a pickle file with file_name. The method will also return the trained model, but it's best to save it to a file
h = df.hmm_train(
states = hidden_states,
observables = observables,
var_column = 'moving',
trans_probs = t_prob,
emiss_probs = em_prob,
start_probs = None,
iterations = 3,
hmm_iterations = 100,
tol = 2,
t_column = 't',
bin_time = 60,
test_size = 10,
file_name = 'tutorial_hmm.pkl', # replace with your own file name. If you already have a pickle file named this, it will test the first iteration against it.
verbose = False)
# If verbose is True it will print to screen the logliklihood score of each hmm iteration
Iteration 1 of 3
True Convergence:True
Final log liklihood score:-71355.25073897192
Iteration 2 of 3
True Convergence:True
Final log liklihood score:-71387.66974287847
Iteration 3 of 3
True Convergence:True
Final log liklihood score:-71382.64987334394
Starting probabilty table:
| | Deep sleep | Light sleep | Light awake | Active awake |
|----|--------------|---------------|---------------|----------------|
| 0 | 0 | 0 | 0.25689 | 0.74311 |
Transition probabilty table:
| | Deep sleep | Light sleep | Light awake | Active awake |
|--------------|--------------|---------------|---------------|----------------|
| Deep sleep | 0.154846 | 0.481724 | 0.363429 | 0 |
| Light sleep | 0.602652 | 0.337834 | 0.0595133 | 0 |
| Light awake | 0 | 0.243226 | 0.744384 | 0.0123892 |
| Active awake | 0 | 0 | 0.0165169 | 0.983483 |
Emission probabilty table:
| | Inactive | Active |
|--------------|------------|----------|
| Deep sleep | 1 | 0 |
| Light sleep | 1 | 0 |
| Light awake | 0.175193 | 0.824807 |
| Active awake | 0.0207276 | 0.979272 |
# if .hmm_train() has an argument for the file_name parameter a pickle copy of the trained HMM will be saved to your local
# Use the below to load the trained model for analysis
with open('./tutorial_hmm.pkl', 'rb') as file:
h = pickle.load(file)
4. Plotting the decoded data
# Lets have a look at our trained HMM
# Here we can see the transition rates between the difference states
df.hmm_display(hmm = h, states = hidden_states, observables = observables)
Starting probabilty table:
| | Deep sleep | Light sleep | Light awake | Active awake |
|----|--------------|---------------|---------------|----------------|
| 0 | 0 | 0 | 0.25689 | 0.74311 |
Transition probabilty table:
| | Deep sleep | Light sleep | Light awake | Active awake |
|--------------|--------------|---------------|---------------|----------------|
| Deep sleep | 0.154846 | 0.481724 | 0.363429 | 0 |
| Light sleep | 0.602652 | 0.337834 | 0.0595133 | 0 |
| Light awake | 0 | 0.243226 | 0.744384 | 0.0123892 |
| Active awake | 0 | 0 | 0.0165169 | 0.983483 |
Emission probabilty table:
| | Inactive | Active |
|--------------|------------|----------|
| Deep sleep | 1 | 0 |
| Light sleep | 1 | 0 |
| Light awake | 0.175193 | 0.824807 |
| Active awake | 0.0207276 | 0.979272 |
# Ethoscopy also has pretrained HMMs for both Male and Female CS Drosophila, trained on several days worth of data on hundreds of flies
# These have the state structure of the above
# Feel free to use these when looking at your own wildtype datasets, however if using other species or mutants you will need to train your own
# For the rest of this tutorial we'll use a the Male pretrained model
# first we need to import the get_HMM function
from ethoscopy.misc.get_HMM import get_HMM
# Have the argument as "M" or "F" for the male or female dataset respectively
h = get_HMM("M")
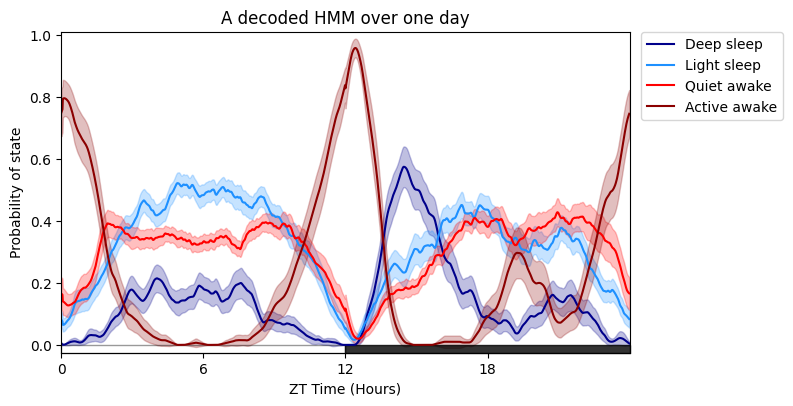
# Plotting the specimens HMM overtime is much like plot_overtime(), except you cannot facet by the metadata, see split plots below!
# The only addtional arguments are for the trained HMM, the label names for each state and their colours, and also the time each row is binned when it was trained, i.e. 60 seconds (default)
# If you wish to follow our naming and colour schema then leave labels and colours as None, if you have a 4 state model it will use the labels as seen above and our blue/red colour scheme
# You can change day_length, lights_off, title, grids as seen previously
# Save plots giving an arugment to parameter save with the location and file type to be saved as, see overview tutorial for more information
fig = df.plot_hmm_overtime(
hmm = h,
variable = 'moving',
wrapped = True,
t_bin = 60,
title = 'A decoded HMM over one day'
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
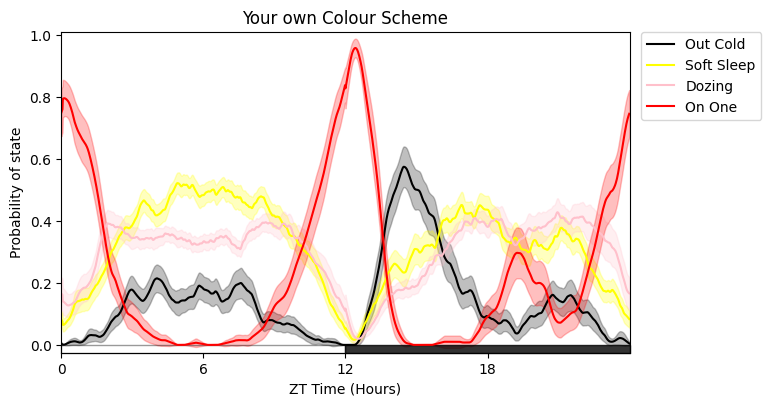
# Here's it with new names and different colours
# The colours must follow Plotlys colour naming convention
fig = df.plot_hmm_overtime(
hmm = h,
t_bin = 60,
variable = 'moving',
labels = ['Out Cold', 'Soft Sleep', 'Dozing', 'On One'],
colours = ['black', 'yellow', 'pink', 'red'],
wrapped = True,
title = 'Your own Colour Scheme'
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
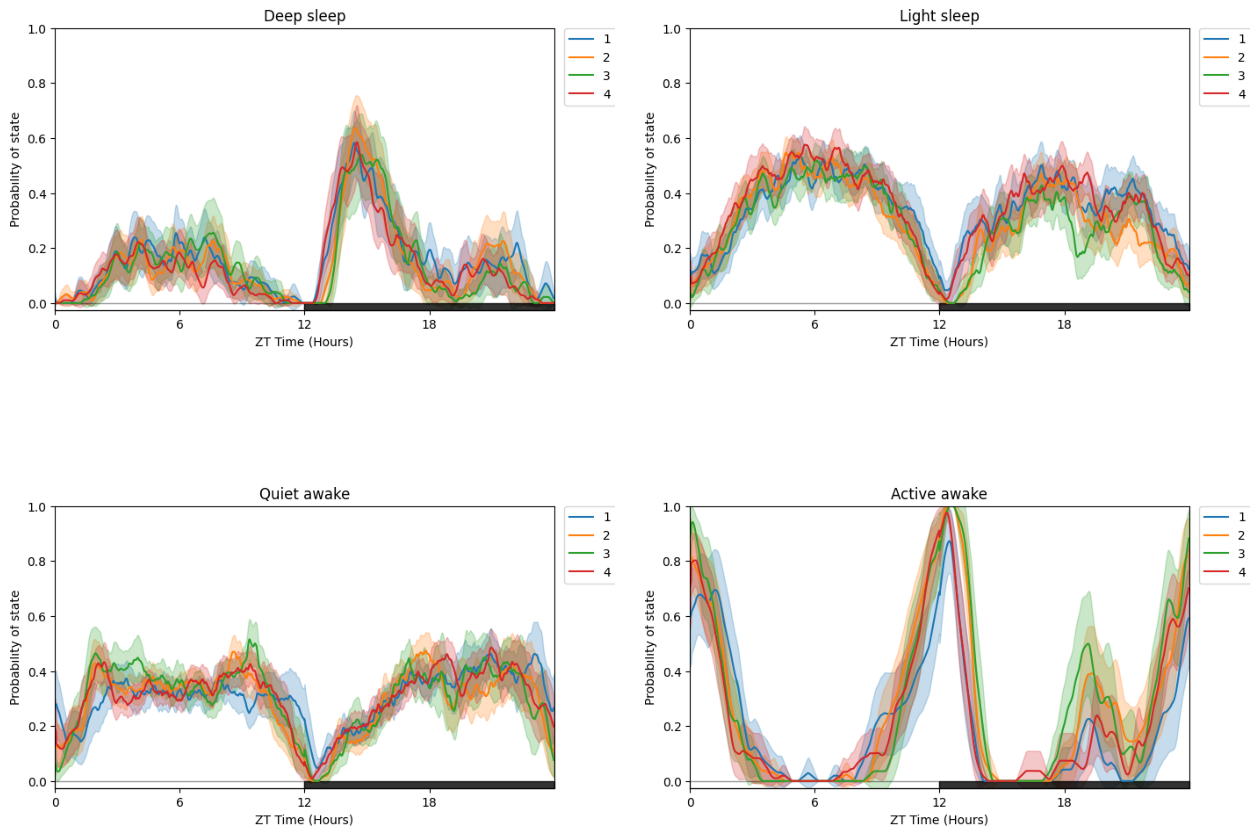
# Due to having multiple states plotted at once its easier to compare by faceting with multiple plots for each states
# plot_hmm_split is the same as plot_hmm_overtime, but with the facet_labels, facet_col, facet_arg parameters we've seen before to compare via our metadata
fig = df.plot_hmm_split(
hmm = h,
variable = 'moving',
facet_col = 'exp_group',
wrapped = True,
t_bin = 60,
title = "Split plot per Experimental Group"
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
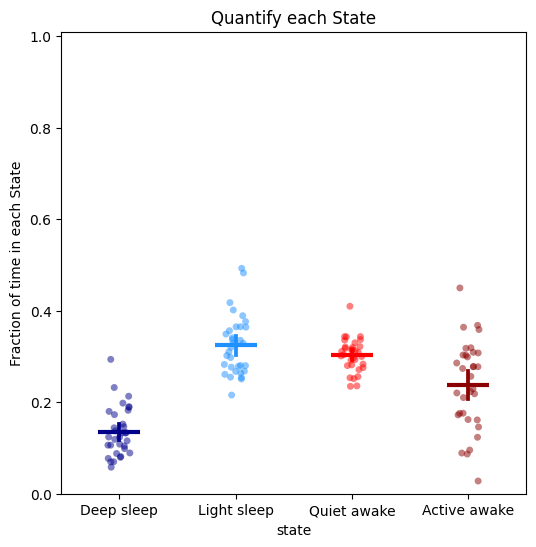
# To quantify the above just call the plot_hmm_quantify method
# Like all the quantify methods it will also return a dataframe with the values of each plotted dot for you to do any statistical analysis
fig, stats_time = df.plot_hmm_quantify(
hmm = h,
t_bin = 60,
variable = 'moving',
title = "Quantify each State"
)
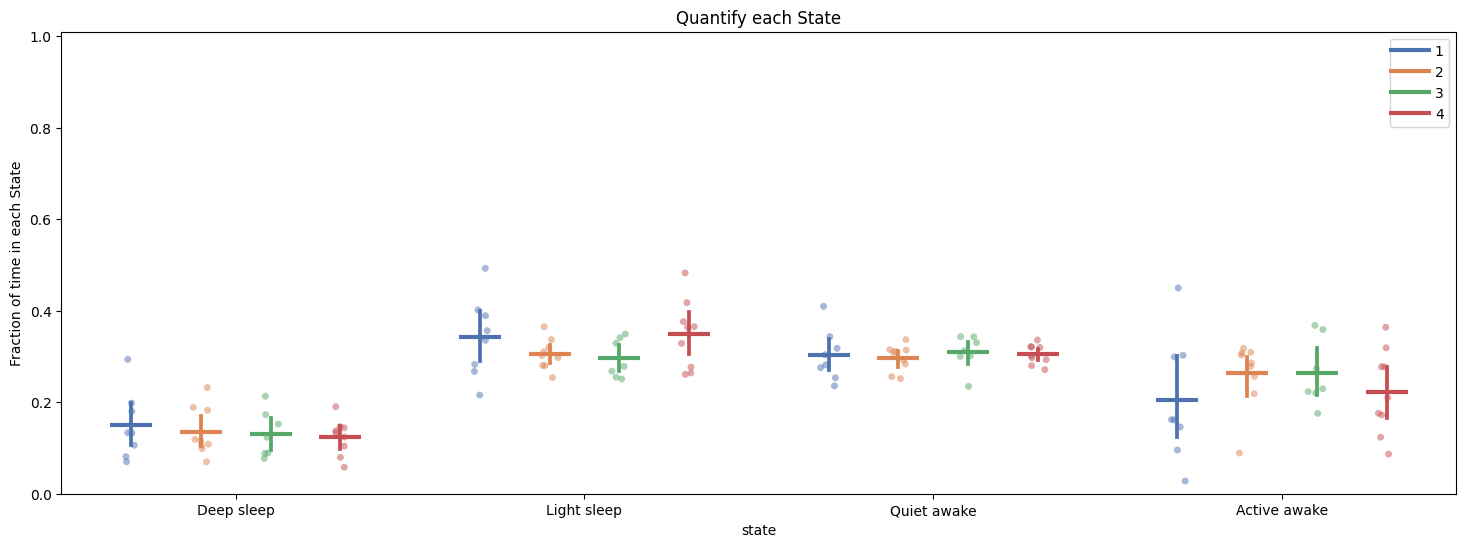
fig, stats_hmm = df.plot_hmm_quantify(
hmm = h,
t_bin = 60,
variable = 'moving',
facet_col = 'exp_group',
title = "Quantify each State"
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
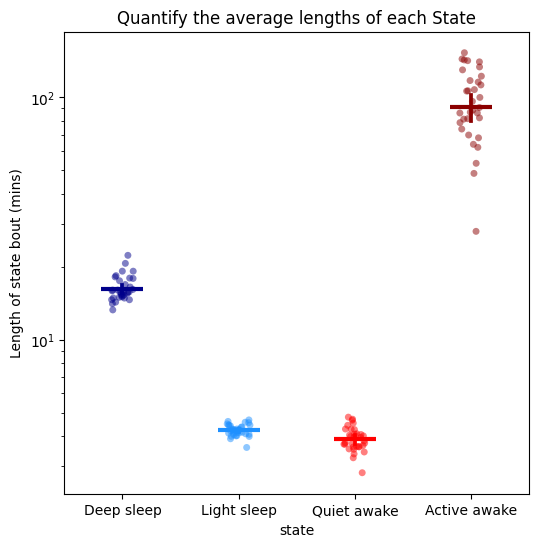
# When getting to grips with your new model you don't want to look at just the time in each state, you also need to understand the rules the HMM has decided
# One of the best ways to do this is by looking at the average length of each state
fig, stats_length = df.plot_hmm_quantify_length(
hmm = h,
t_bin = 60,
variable = 'moving',
title = "Quantify the average lengths of each State"
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
# The average is useful, but it doesn't tell us about about how time influences the decision by the model to predict each state
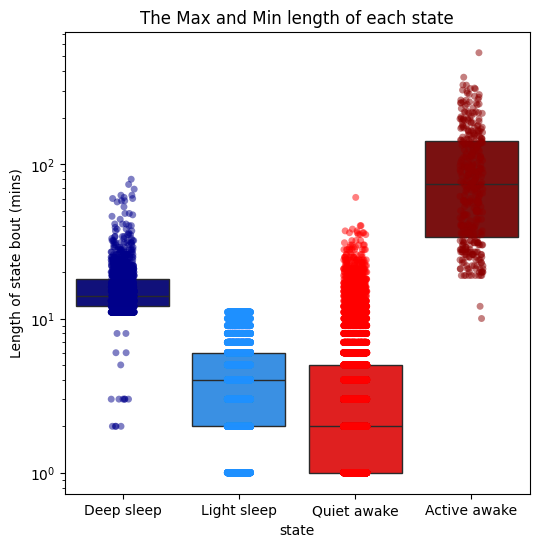
# Use plot_hmm_quantify_length_min_max to see the maximum and mimimum length of each state to understand when the model switches it's predictions
# Here we can see that light sleep can only be 11 minutes of inactivity long, after that it is predicted as deep sleep
fig = df.plot_hmm_quantify_length_min_max(
hmm = h,
t_bin = 60,
variable = 'moving',
title = "The Max and Min length of each state"
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1668: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(_wrapped_remove_first_last_bout),
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
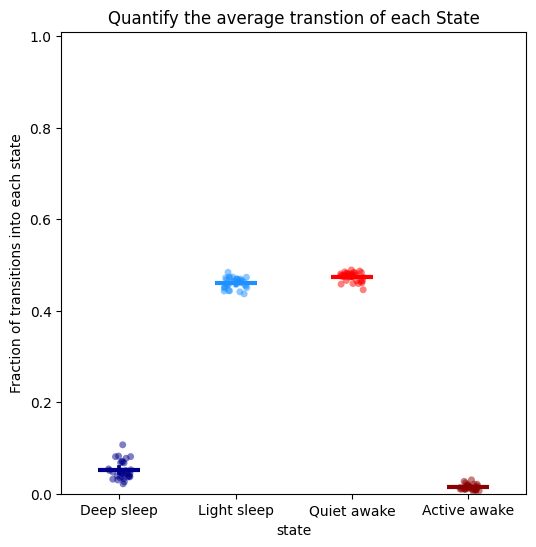
# It is also useful to see how often a state is transitioned into, to understand its frequency in relation to length
# Here we can see the two light sleep and awake stages are transitioned into often, which compliments their low run lengths
# In contrast the other two states are transitioned into less frequently, but when they do the it is for a lot longer
fig, stats_transition = df.plot_hmm_quantify_transition(
hmm = h,
t_bin = 60,
variable = 'moving',
title = "Quantify the average transtion of each State"
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1668: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(_wrapped_remove_first_last_bout),
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
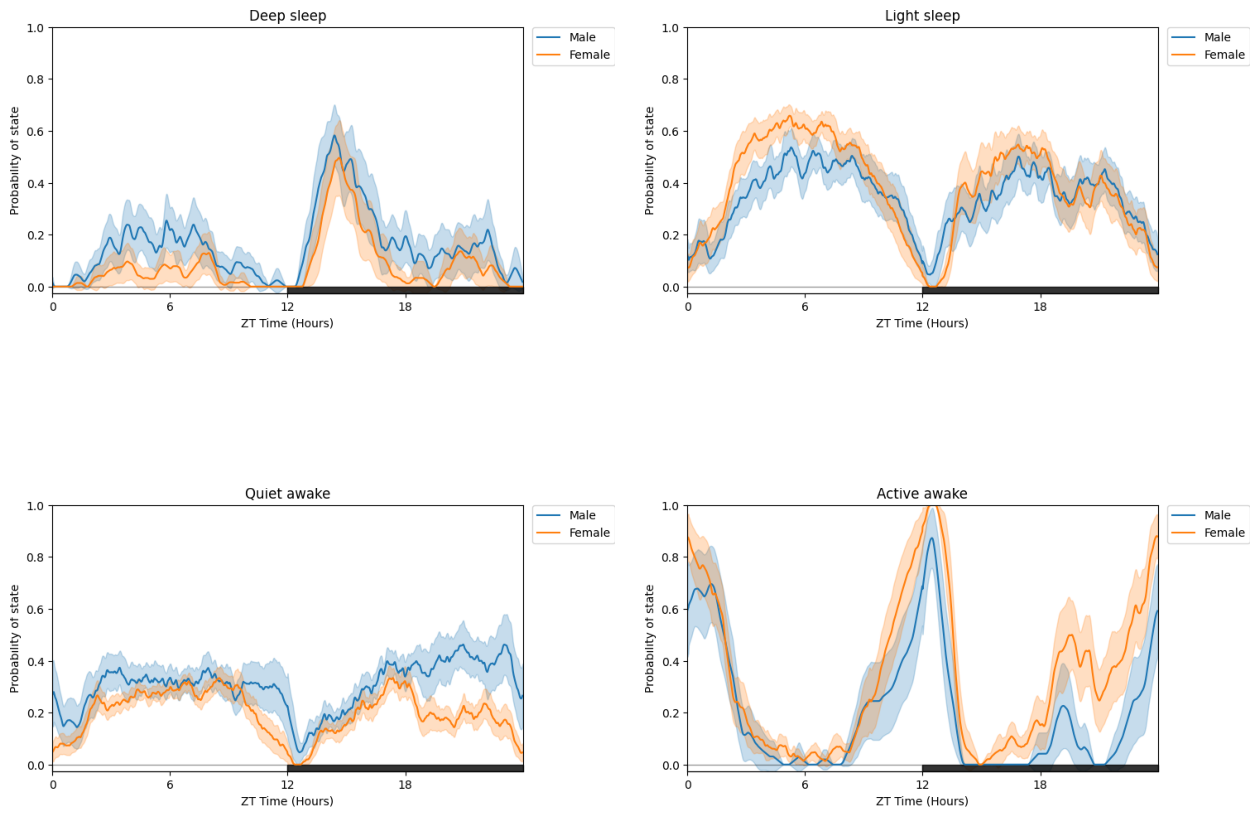
# All of the above (except plot_hmm_overtime) can take arguments of multiple trained HMMs with the view that can compare different species, mutants, ect.
# For example to demonstrate we can take this dataset and compare two groups, one using the male trained model and the other the female trained model
# When you have multiple HMMs you must have the same number of arguments, labels, and bins. Otherwise you will raise an error
# Try this out with the other plotting functions!
h_f = get_HMM("F")
fig = df.plot_hmm_split(
hmm = [h, h_f],
variable = 'moving',
facet_col = 'exp_group',
facet_arg = [1, 2],
facet_labels = ['Male', 'Female'],
wrapped = True,
t_bin = [60, 60],
title = "Split plot with two different HMMs"
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
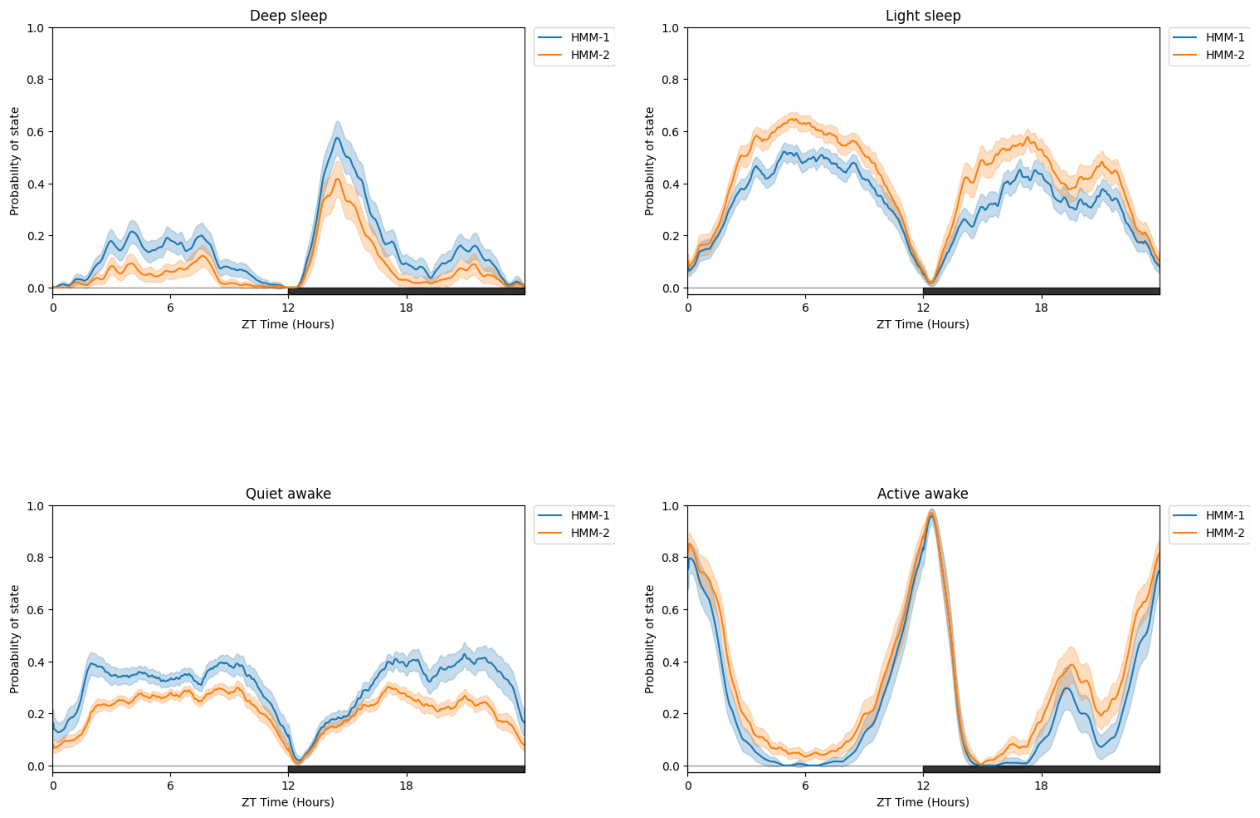
# You can also compare differently trained HMMS (such as different architecture or number of states) on the same dataset
# just call a list of HMMs but no facet_col
fig = df.plot_hmm_split(
hmm = [h, h_f],
variable = 'moving',
wrapped = True,
t_bin = [60, 60],
title = "Split plot with two different HMMs on the same data"
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
# Finally, sometimes you want to see the decoded data minute by minute to get to understand it properly
# Like the others you can have multiple HMMs, if you choose to do this then it will display the same specimen but decoded by each HMM
# The ID of each specimen will be printed to screen in case you want to investigate further as each ID is picked randomly each time it's run. Isolate by using .xmv()
fig = df.plot_hmm_raw(
hmm = h,
variable = 'moving',
num_plots = 3, # the number of different specimens you want in the plot
t_bin = 60,
title = 'Raw plots'
)
# Sometimes it won't work if the randomnly chosen specimen has no data. In these cases re-run the cell
# Addtionally, if you have response data from mAGO experiments you can add that behavpy dataframe to highlight points of interaction and their response
# Purple = response, lime = no response
# This is only avaiable in the Plotly version
## df.plot_hmm_raw(stimuli_df = stim_df, hmm = h, variable = 'moving', num_plots = 5, bin = 60, title = '', save = False)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
Plotting: 2016-04-04_17-39-05_009aee|17
Plotting: 2016-04-04_17-39-22_033aee|03
Plotting: 2016-04-04_17-39-22_033aee|19
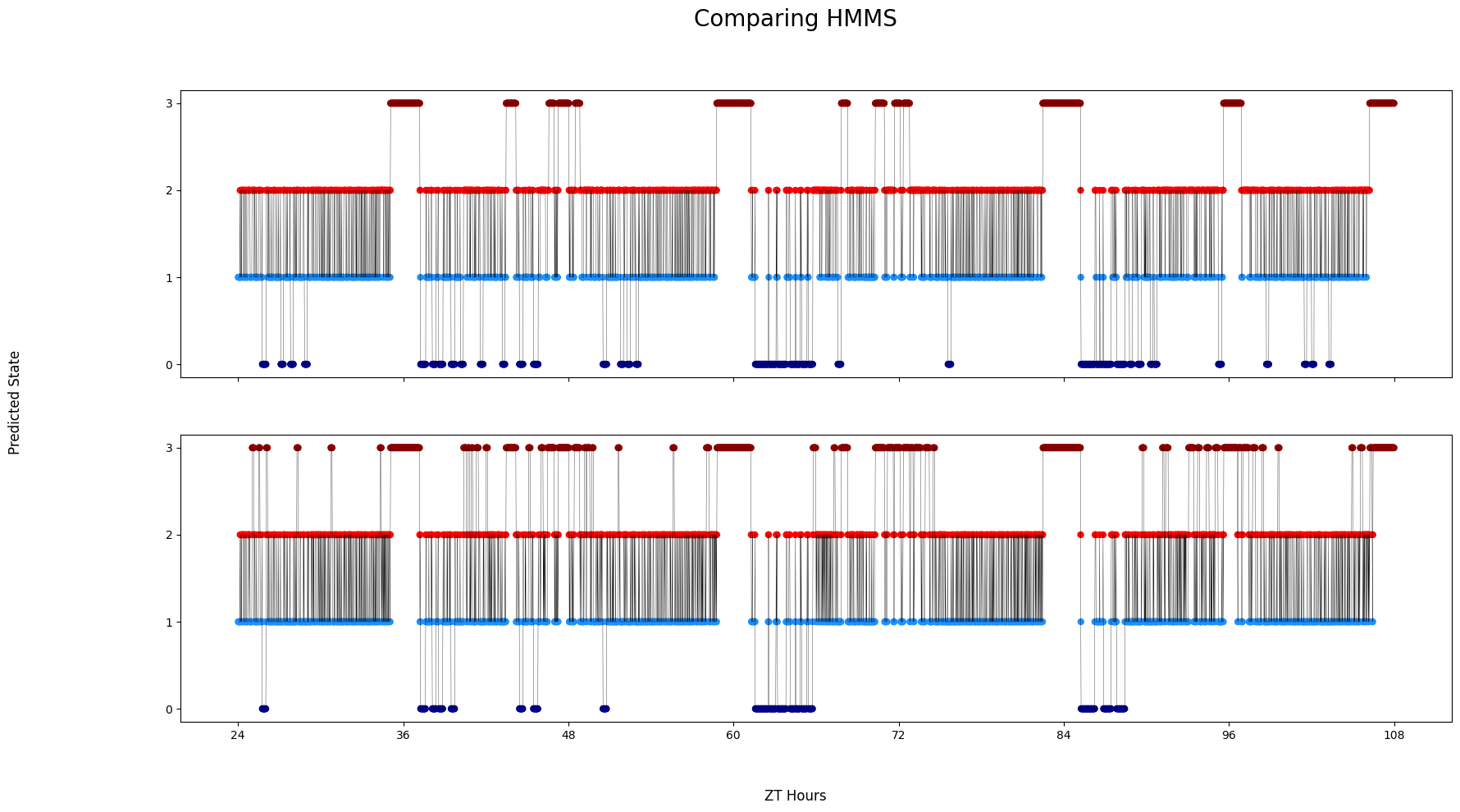
# Like before you can compare HMMs if you provide them as a list
# A random specimen will be chosen and each HMM will be decode it
fig = df.plot_hmm_raw(
hmm = [h, h_f],
t_bin = [60, 60],
variable = 'moving',
title = 'Comparing HMMS'
)
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
/home/gg/Code/ethoscope_project/ethoscopy/src/ethoscopy/behavpy_core.py:1605: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tdf.groupby("id", group_keys=False).apply(
Plotting: 2016-04-04_17-39-05_009aee|11
Plotting: 2016-04-04_17-39-05_009aee|11